销售预测爆旺(scikit-learn版本)
悼念一下回归模型的悲剧,先尝试一下分类模型,稍后再整他
1 数据探索
sparkSQL支持用sql对数据集进行分析,数据探索工作仍然大部分放在spark中来完成
1.1 🔑发现的一些相关性
对应的数值越接近1表示正相关性越大,越接近-1表示负相关性越大,越接近0表示相关性越小
- 销售额的相关度往往好于销量
- 毛利率、销量以及库存周转率的权衡在销售额上综合体现了?
- 销售任务的导向作用?
排除极low款与爆款的前提下
- 新货前30天预测后30天相关性较大
新货前30天预测整个商品季相关性较大
- 放开爆款,反而销量的相关度上去了
- 销售额的相关度有所下降
- 冬装数据太奇葩了,基本依托于两个大活动走货
- 考虑要把冬装单独拆分出模型来搞
- 其它季节货品使用一个预测模型
- 只保留冬季的情况




1.2 决定尝试分offset构建模型
1.2.1 预测商品级销量分类段划分:offset_total_quantity
| Offset(销量) | 正分类(大于offset) | 负分类(小于offset) |
|---|---|---|
| 1000 | 1477 | 4471 |
| 1600 | 1016 | 4932 |
| 10000 | 204 | 5744 |
| 50000 | 16 | 5932 |
1.2.2 参考周期划分:
重点调优放在前三个档,因为参考周期太长,预测的意义也就小了
- 前3天:offset3_quantity
- 前7天:offset7_quantity
- 前15天:offset15_quantity
- 前30天:offset30_quantity
2 开撸
代码的注释基本都用的英文,不是为了装逼,是怕有字符集兼容问题。。。
2.1 包引入
大致分为三类: 数据操作类、sklearn相关、可视化相关。
1 | # package import |
核心包简介
- pandas: 数据集读取操作查询转换输出库。
- sklearn: scikit-learn提供的ML相关方法实现库。
- preprocessing: 特征预处理相关。
- model_selection: model所需的数据集选取生成。
- metrics: 模型效果评估相关方法。
- externals: 模型持久化相关。
- plotly: 发现的一个第三方可视化库,比matplotlib操作起来简单,生成图形可以交互分享,但是间歇性被墙。。😂
2. 辅助函数声明
2.1 生成对应offset的类标
类标生成辅助方法,方法会塞入到pandas dataframe的apply方法中,默认会传入row
1 | def gen_hot_product_label(row, offset, column_index): |
2.2 特征变换
减少特征之间或者特征与类标之间取值差距,blablabla
方法
log辅助方法
1 | def log_quantity(row, column_index): |
标准化转换
1 | from sklearn.preprocessing import StandardScaler |
min-Max转换
1 | from sklearn.preprocessing import MinMaxScaler |
2.3 样本均匀化
前情回顾
正负样本分布不均匀,需要均匀化处理,使得正负样本数基本一致。
隆重介绍imblearn库,提供各种样本均匀化算法的实现。
| Offset(销量) | 正分类(大于offset) | 负分类(小于offset) |
|---|---|---|
| 1000 | 1477 | 4471 |
| 1600 | 1016 | 4932 |
| 10000 | 204 | 5744 |
| 50000 | 16 | 5932 |
under-sampling
把多的砍掉,正样本多就砍正样本,负样本多就砍负样本的,最后就一致了。
至于如何砍就有很多算法了,这里选用了NearMiss算法。
1 | from imblearn.under_sampling import NearMiss |
over-sampling
哪种样本少了,就想办法造一些,最后就一致了。
至于如何造就有很多算法了,这里选用了SMOTE的SVM模式算法。
1 | from imblearn.over_sampling import SMOTE, ADASYN |
2.4 模型算法
最简单的是感知器算法,因为不能解决线性不可分问题,就忽略掉了。。
逻辑斯蒂回归
唬人的名字,说是回归,其实是分类算法。。
分类界用的很多。
1 | from sklearn.linear_model import LogisticRegression |
随机森林
理论上说可以忽略样本分布不均匀的问题(因为属于决策树类的算法)。
1 | from sklearn.ensemble import RandomForestClassifier |
SVM
忽然概念名词超多的算法,什么超平面啥的。。
1 | from sklearn.svm import SVC |
GBDT
梯度提升算法(实测在这个场景综合效果较好😘)
1 | from sklearn.ensemble import GradientBoostingClassifier |
xgboost
在kaggle大赛中叱咤风云的神级算法,在这个场景实测效果不如GBDT
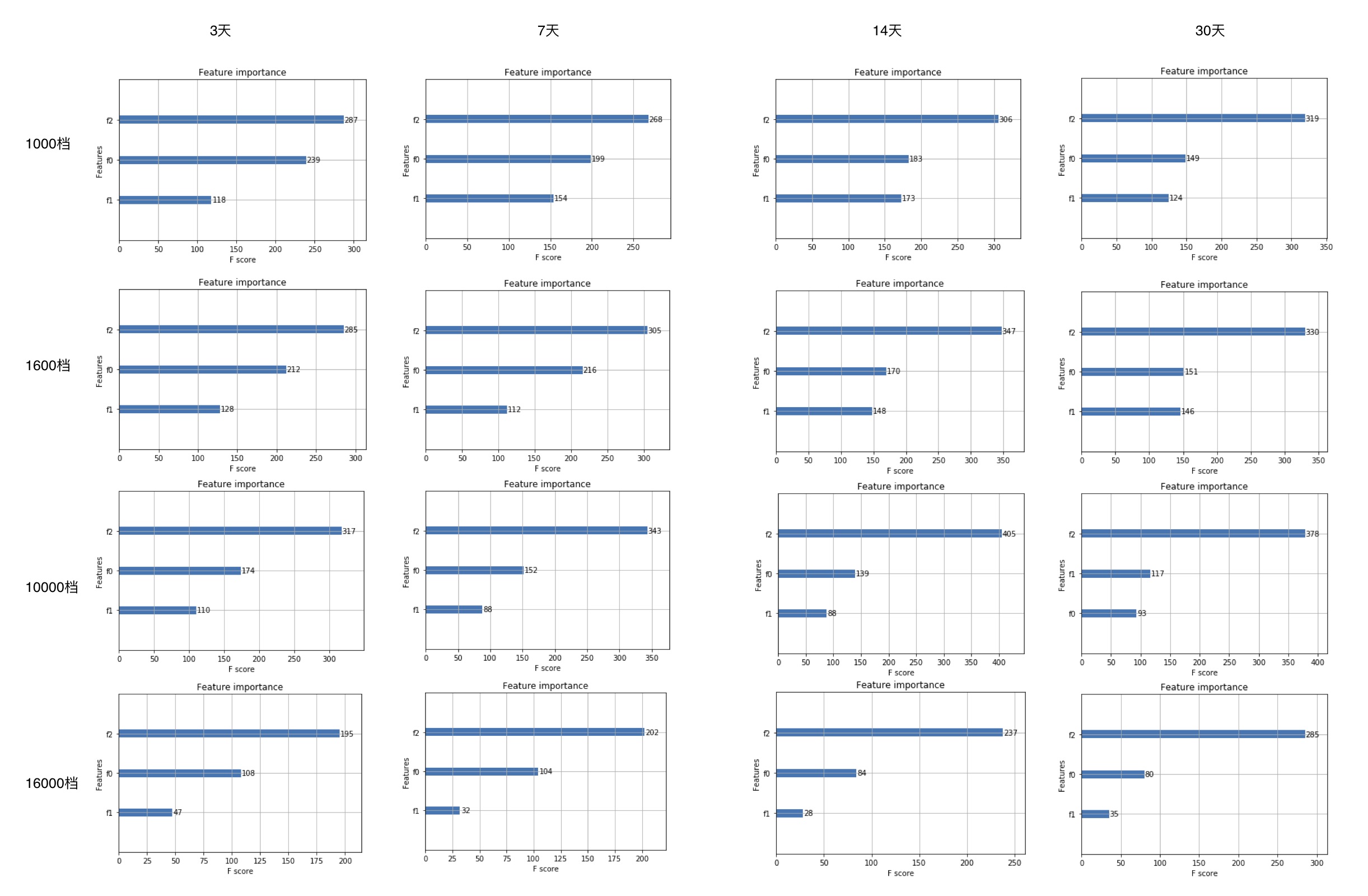
但xg有些好处,比如可以输出每轮学习时的精确度,以及输出目前输入特征的重要性分数,便于优化调参。
1 | from xgboost import XGBClassifier |
2.5 预测类
SalesProphet(销售预言家):预测辅助类
因为各种特征offset、类标、算法的组合,不封装一个类的话,将来会死的。。(已经死过一轮了,改一个东东要累死。。)
具体方法作用详见注释哈,总之就是传入参数,调用predit完事。
(吐槽python 断言竟然只能在继承于testcase的类中使用。。)
1 | class SalesProphet(object): |
3. 数据准备
3.1 数据读取
从spark 导出准备好的数据到csv文件,pandas读取该csv中的数据。
1 | train_data = pd.read_csv("data/product_2016_offset_group.csv") |
获取前5条数据看看情况
1 | train_data.head() |
describe 可以对df中各列的综合指标进行集中展示。
比如中位数、均值等等,方便进一步分析数据。
1 | train_data.describe() |
3.2 销量特征log变换
1 | train_data['log_3_quantity'] = train_data.apply(log_quantity, column_index=8, axis=1) |
1 | train_data.head() |
3.3 类标生成
1 | train_data['hot_1000_product'] = train_data.apply(gen_hot_product_label, args=(1000, 12), axis=1) |
1 | train_data.head() |
product_code 1477
category_id 1477
season 1477
offset3_amount_actual 1477
offset7_amount_actual 1477
offset15_amount_actual 1477
offset30_amount_actual 1477
offset_total_amount_actual 1477
offset3_quantity 1477
offset7_quantity 1477
offset15_quantity 1477
offset30_quantity 1477
offset_total_quantity 1477
log_3_quantity 1477
log_7_quantity 1477
log_15_quantity 1477
log_30_quantity 1477
log_total_quantity 1477
hot_1000_product 1477
hot_1600_product 1477
hot_10000_product 1477
hot_50000_product 1477
dtype: int64
3.4 数据清洗
1 | train_data_normal = train_data[train_data.offset30_quantity <= train_data.offset_total_quantity] |
1 | train_data_normal[train_data_normal.offset_total_quantity < 0] |
1 | # drop null row |
product_code 0
category_id 0
season 0
offset3_amount_actual 0
offset7_amount_actual 0
offset15_amount_actual 0
offset30_amount_actual 0
offset_total_amount_actual 0
offset3_quantity 0
offset7_quantity 0
offset15_quantity 0
offset30_quantity 0
offset_total_quantity 0
log_3_quantity 0
log_7_quantity 0
log_15_quantity 0
log_30_quantity 0
log_total_quantity 0
hot_1000_product 0
hot_1600_product 0
hot_10000_product 0
hot_50000_product 0
dtype: int64
- 无序特征做onehot消除次序关系。
- 整理特征与类标。
- 循环生成预言家,让它预测,生成报告,然后把他丢到预言家数组里面(salesProphets)便于后面生成分析对比用的DataFrame。
1 | # category_id, season onehot |
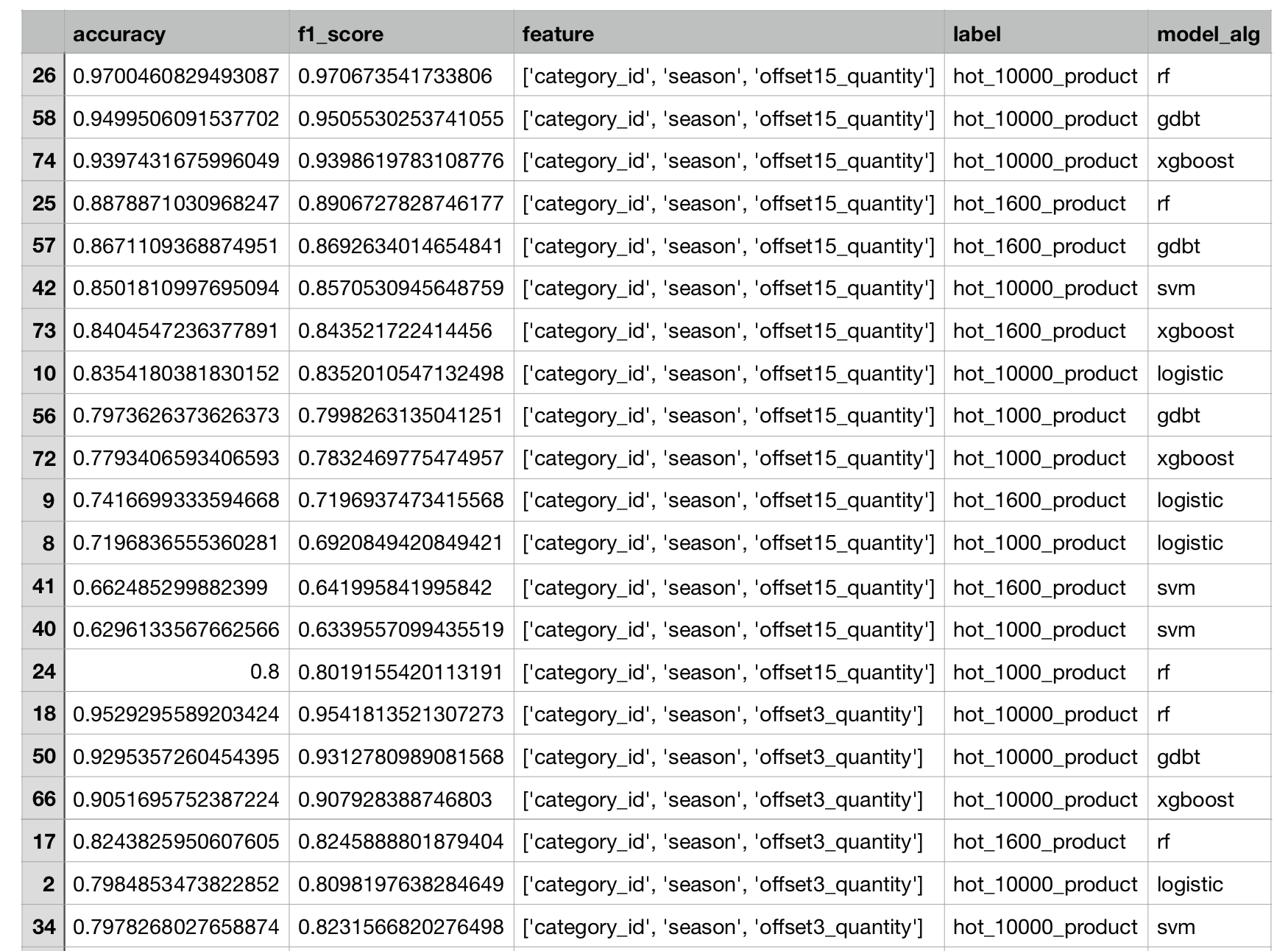
预言家数组生成综合对比DataFrame
1 | # 整理生成报告DataFrame |
分析报告保存
1 | result_df.to_csv('data/result_df.csv') |
结果
特征重要性分析
分数越高越重要
综合对比
分数越接近1越好