销售预测案例源码分析
本文重在借案例学习spark相关数据结构与语法
流程
1. 特征转换
1 | val stateHolidayIndexer = new StringIndexer() |
先转化为StringIndexer
- inputCol原始列
outputCol转化为对应的index列:
- 从0开始编号,出现频次最多的项目,编号小
- 有时候会有着这样的场景
用一个df转换另一个df,当df2对应列中的值超出了df1中的范围时,可以选择策略
- skip:忽略掉
- keep:超出项对应分配一个index
默认为抛出异常
1
val indexed2 = indexer.fit(df1).setHandleInvalid("skip").transform(df2)
做OneHotEncoder
- 转化为对应向量
- 只指定一位为1,其余为0,出现频率最低的为(最终序号, [], [])
- VectorAssembler
- 将对应元素合并成一个向量,打平
2. 环境初始化(面向像我这样的小白选手)
main中 大部分抄袭文档
1 | val conf = new SparkConf().setAppName("alithink").setMaster("local") |
- SparkConf:
- Spark各种key-value的配置项
- setAppName: 给你的应用配置一个名字
- setMaster: 连接到的主URL,例如这里的local代表本地单线程运行,local[4]本地4核运行,或者spark://master:7077 spark典型的Mater/slave模式
- Spark各种key-value的配置项
- SparkContext:
- 理解为与spark集群的对接人,可以用她来创建RDDs, accumulators 和 broadcast variables
- 每个JVM环境活着的SparkContext只有一个,创建一个新的前先stop(将来这个限制可能会被移除)
SparkSession:
- 合并了SparkContext和SQLContext
- 内部有对应属性在需要时可以取得对应实例
- 用于操作DataSet和DataFrame API
使用:
- REPL已经预先创建了(比如spark-shell, zeppelin)
获取已经存在的或者新创建一个:
SparkSession.builder().getOrCreate()- 前提是sparkContext已经创建
尽量用SparkSession来接管一切吧(上述代码可以改为如下)
1
2
3
4
5
6
7
8
9val conf = new SparkConf().setAppName("alithink").setMaster("local")
// val sc = new SparkContext(conf)
// val sparkSession = SparkSession.builder().getOrCreate()
val sparkSession = SparkSession.builder
//.master("local")
//.appName("alithink")
.config(conf)
.getOrCreate()
- 合并了SparkContext和SQLContext
3. 训练数据整理
1 | // main中调用 |
1 | // 具体实现函数 |
- SparkSession:
- read 返回一个DataFrameReader
- format(读取格式):com.databricks.spark.csv期初为一个开源库,后来已经集成到spark2.*啦
option("header", "true")使用第一行作为头- 赠送
.option("inferSchema", "true")自动推导类型
- read 返回一个DataFrameReader
- DataFrame(粗略一说,内容太多^_^):
- DataSet[Row]
- DataFrame vs RDD
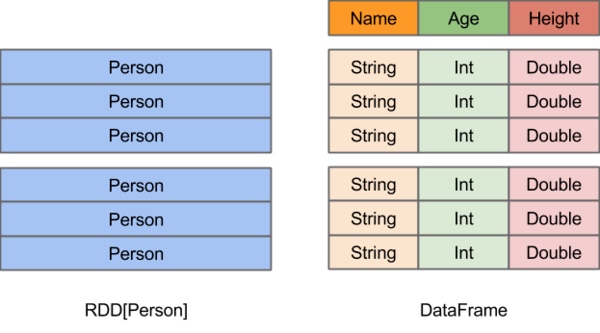
- DataFrame vs DataSet
- 往往区别是在于行类型的不确定与确定
- DataSet:
- repartition: 返回按规则分区后的dataset
- 一句话:分区由少变多,或者在一些不是键值对的RDD中想要重新分区的话,就需要使用repartition了
- 有多变少,直接coalesce,repartition其实就是shuffle=true的coalesce
- 关于分区:分区的个数决定了并行计算的粒度
- 详情参考:知乎传送门
- createOrReplaceTempView:
- 创建本地临时‘表’,便于之后sql操作
- repartition: 返回按规则分区后的dataset
- sql:
- na.drop() 丢掉所有包含null的row
4. 线性回归(随机森林类似,换了方法以及ParamMaps)
1 | def preppedLRPipeline():TrainValidationSplit = { |
- 首先划分训练集和测试集
- fit:
- 用训练集拟合出一个model
- RegressionMetrics:
- 回归evaluator
- 集中评估标准:
- R^2:决定系数,反应因变量的全部变异能通过回归关系被自变量解释的比例。如R平方为0.8,则表示回归关系可以解释因变量80%的变异。换句话说,如果我们能控制自变量不变,则因变量的变异程度会减少80%
- explainedVariance: 解释方差,具体详见:http://blog.sciencenet.cn/blog-1148346-852482.html
- MAE mean absolute error: 绝对误差,准确值与其测量值之间的误差。
- MSE mean squared error: 均方误差, 衡量平均误差的方法。
- RMSE root mean square error: 均方根误差。
- 最后用训练好的模型transform测试集,然后将结果保存。