智子环境搭建历程
智子 - 韩都衣舍机器学习平台代号😋
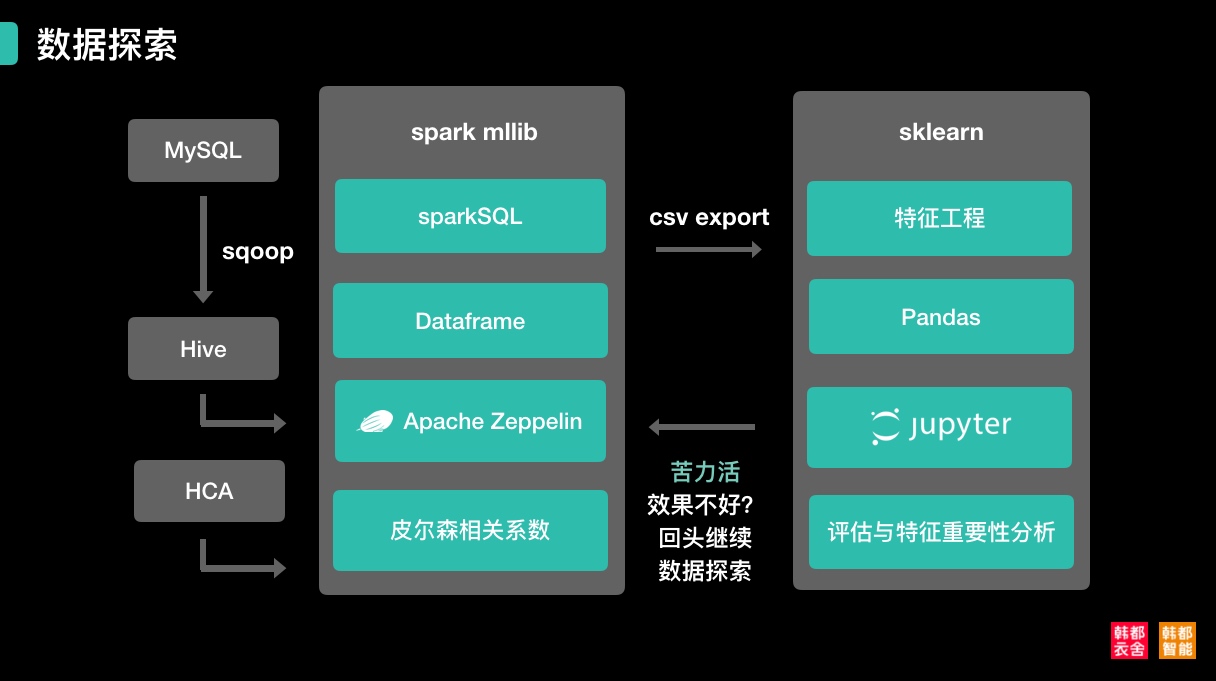
一、spark流派
1.1 hadoop
起初选择使用CDH安装(原因:老环境就用的这个,据说比较稳定),然而在双节点情况下总是出现莫名问题。磕磕绊绊安装好了,实际用起来还是有不少问题(集成环境问题定位好麻烦。。),在尝试几波之后最终选择放弃(期间还麻烦运维妹子重做了系统😂)。想到实际需要的功能并不太多,果断转为人工安装部署。
CDH的安装部署过程作为番外放在最后面吧。。。
版本选择
虽然没有安装CDH,还是选用了CDH版的hadoop2.6。(据说体质较好,比较稳健)
文章参考
坑位介绍
主要记录自己部署时遇到的主要问题,详细步骤可以参考上面的文章
💩 jps发现竟然木有DataNode
之前用CDH安装过一遍hadoop导致部分目录有内容残留
- 查看$HADOOP_HOME/etc/hadoop/hdfs-site.xml
- namenode路径
- datanode路径
- 删除对应目录下的所有文件
- 重新执行namenode -format
- 重启hadoop start-all.sh
💩 各种Permission denied
- 先查看各路径是否正确赋权给了hadoop用户
- 没有的chown -R hadoop:hadoop 对应路径
- 当前用户是否已经切换成hadoop用户再执行相关启动命令
💩 没有SecondaryNode了
- 配置$HADOOP_HOME/etc/hadoop/hdfs-site.xml
- name: dfs.namenode.secondary.http-address
- value: 0.0.0.0:50090
1.2 hive
版本选择
目前最新版:apache-hive-2.3.2-bin
文章参考
坑位介绍
💩 启动时各种缺表
- 查看$HIVE_HOME/scripts/metastore/upgrade/mysql/hive-schema-2.3.0.mysql.sql
- 用root用户登录至mysql
- 创建对应的用户并授权用户(别忘记flush privileges)
- 然后执行这个初始化sql
💩 如何重启hive metastore
- ps -ef |grep HiveMetaStore
- kill -TERM pid
- hive –service hiveserver &
1.3 sqoop
版本选择
官网说了诸多sqoop2的好处,最后建议说生产环境不要使用2…
sqoop1最新版:sqoop-1.4.7.bin__hadoop-2.6.0
文章参考
坑位介绍
💩 发现总是Connection Failure
mysql场景
- 检查hadoop集群每台机器与mysql数据源的连通性
- telnet xx.xx.xx.xx 3306
- 不同的话,申请开通权限即可
💩 报出jackson databind缺少某某方法
- 统一hadoop、hive、sqoop各自lib中jackson的版本
- 选择三者中的最高版本即可
💩 报出hive version与metastore version不一致
- 如果报出hive版本低于metastore版本(跟我一样)
- 关闭版本检查即可
- name: hive.metastore.schema.verification
- value: false
- 如果报出hive版本高于metastore版本:
- 将元数据库mysql中的对应hive库删除
- 用对应版本的script重新初始化元数据表
- 同样禁用掉版本检查吧。。
💩 导入hive报错HIVE_CONF_DIR
- .bashrc添加
- export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
- source .bashrc
1.4 spark
版本选择
从官网下载的时候,记得选择对应的hadoop版本
spark-2.2.1-bin-hadoop2.6
文章参考
过于简单其实也没有参考什么文章。。
1.5 zeppelin
版本选择
这里选择了附带所有interpreter的版本
zeppelin最新版:zeppelin-0.7.3-bin-all
文章参考
CDH安装配置zeppelin-0.7.3以及配置spark查询hive表
坑位介绍
💩 报出jackson版本问题
- 与之前的问题类似,立刻想到将包统一即可。
💩 无法初始化SessionHiveMetaStoreClient
由于配置hive之后,需要将hive-site.xml复制HADOOP_CONF_DIR一份,由于zeppelin(支持hive)也需要加载HADOOP_CONF_DIR目录,所以导致无法加载hive元数据,导致异常,此时启动hive的元数据服务在启动zeppelin即可。
- 拷贝hive-site.xml到$HADOOP_HOME/etc/hadoop
二、sklearn流派
2.1 anaconda与jupyter(猪币特)
版本选择
python3版本:Anaconda3-5.0.1-Linux-x86_64
文章参考
在centos7服务器上安装anaconda和jupyter notebook
坑位介绍
此处应该有掌声,配置太简单了,与spark流派形成鲜明的对比。
没啥特别的坑位需要备忘,一切都水到渠成。
三、数据同步策略
3.1 sqoop同步策略
具体sqoop同步示例
sqoop import -Dorg.apache.sqoop.splitter.allow_text_splitter=true –connect jdbc:mysql://xx.xx.xx.xx/数据库名?characterEncoding=utf-8 –username 数据库用户名 –password 数据库密码 –num-mappers 4 –table 源表名 –hive-import –hive-overwrite –hive-table hive表名 –split-by 切分字段(如果有主键默认使用主键)
效果
- 同步速度真心快。(为什么会这么快呢?3000多万的表15分钟左右)
- hive源数据放置在磁盘中,无需全部加载入内存再进行筛选处理。
- 似乎对于源数据库压力不大。
- 最终选定该方案。
3.2 mysql直接拉取csv
在sqoop环境起初搭建不顺利的背景下提出的备选方案。
同步示例
mysql -u数据库用户名 -p数据库密码 -hxx.xx.xx.xx 数据库名 -B -e “select * from `表名`;” | sed ‘s/\t/“,”/g;s/^/“/;s/$/“/;s/\n//g’ > 导出的csv名
效果
- 同步速度较sqoop慢一些。(3000多万的表半个小时左右)
- 配置简单,只要网络通即可。
- csv文件较大,直接用pandas读取的话,内存占用会暴涨。
- 不过pandas的大数据集处理速度还是挺快的。
- 小数据集场景灵活使用。
四、总结
经此一役,收获颇多,除了获取知识之外,也总结了几则六字真言,与君共勉。
- 多备份,少吃亏
- 多联想,勤记录
- 多虚拟,后物理
- 多尝试,不放弃
五、番外
CDH篇
- 修改hostname hostnamectl set-hostname
- 配置hosts
- 创建用户hadoop adduser
- passwd
- 配置visudo
- reboot
- 切换至hadoop用户:
- ssh免密配置
- ssh-keygen -t rsa -P “”
- cat id_rsa.pub >> authorized_keys
- 多服务器配置同步到master
- scp id_rsa.pub sophonmaster:/home/hadoop/.ssh/id_rsa.pub.s1
- cat id_rsa.pub.s1 >> authorized_keys
- ssh免密配置
- root用户密码未知,新创建hadoop用户,配置对应密码
- visudo
- hadoop ALL=(root)NOPASSWD:ALL
- wheel nopasswd放开
- visudo
- 消除警告:

- echo 0 > /proc/sys/vm/swappiness
- echo never > /sys/kernel/mm/transparent_hugepage/defrag
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
- 关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
- systemctl status firewalld
- 关闭SELinux(centos7 默认关闭)
- /etc/selinux/config
- 常规CDH安装方式:
- 将cloudera-manager.repo文件拷贝到所有节点的/etc/yum.repos.d/文件夹下
- 验证repo文件是否起效
- yum list|grep cloudera
- 如果列出的不是你安装的版本,执行下面命令重试
- yum clean all
- yum list | grep cloudera
- 将之前下载的rpms文件拷贝到所有节点下(任意目录)
- 切换到rpms目录下,执行
- yum -y install *.rpm
- 将之前下载的Parcel那3个文件拷贝到/opt/cloudera/parcel-repo目录下(如果没有该目录,请自行创建)
- 至此,/opt/cloudera/parcel-repo下面有三个文件: CDH-5.2.0-1.cdh5.2.0.p0.36-el6.parcel,mainfest.json,CDH-5.2.0-1.cdh5.2.0.p0.36-el6.parcel.sha
- 主节点启动manager安装:
- sudo chmod +x ./cloudera-manager-installer.bin
- ./cloudera-manager-installer.bin
- 删除已经存在的db.properties
- mv /etc/cloudera-scm-server/db.properties /etc/cloudera-scm-server/db.properties.bak